Doubao Seed Evolving模型评测:豆包首款无限进步模型
豆包出了没有版本号、升级自动生效的 Doubao Seed Evolving,主打 1M 超长上下文、长程任务和 Token 效率。围绕数据分析网站、三国战役回放、视频生成和简历制作四个场景实测,记录它的速度、稳定性以及目前可用的边界。

豆包出了没有版本号、升级自动生效的 Doubao Seed Evolving,主打 1M 超长上下文、长程任务和 Token 效率。围绕数据分析网站、三国战役回放、视频生成和简历制作四个场景实测,记录它的速度、稳定性以及目前可用的边界。

在 61 个静态 HTML PPT 组件的基础上,把 Skill 进一步升级为动态版本:用入场动画、循环微动效和切换过渡,解决静态 PPT 容易审美疲劳的问题,并沉淀成可复用的动态组件规范。

深度实测 Kimi K3:在 GPT 5.5/5.6 降智龟速期,K3 的整体表现强到惊喜。重点验证了一句话生成 3D 建模与视频的能力,梳理 3D 建模的惊艳表现与视频生成的可用边界,并对比其他模型在同类任务上的差距。

以独立开发者把产品真正推向线上为主线,拆解从快速开发到注册公司、支付申请、数据合规、备案和安全评估等落地关卡:Vibe Coding 可以让产品很快成形,但合法合规不能只靠感觉。
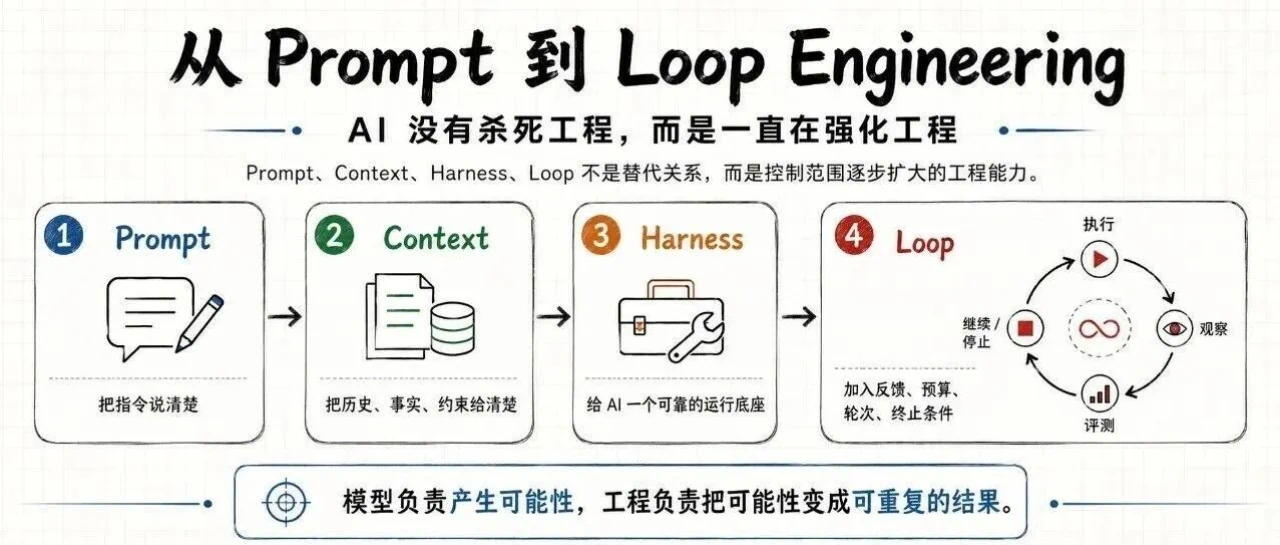
从 Prompt、Context、Harness 到 Loop Engineering,AI 工程的控制范围不断扩大。文章拆解反馈式、事件驱动与爬坡环等循环类型,并说明如何用评测、预算、终止条件和人工关卡,让 Agent 从“能做”走向可验证、可追踪、可持续优化。

从零制作 Codex 桌面宠物的实操攻略:梳理角色设定、动画表现、技能封装与本地运行的关键步骤,也分享 GPT 5.6 Sol 在这一创作流程中的使用体验。
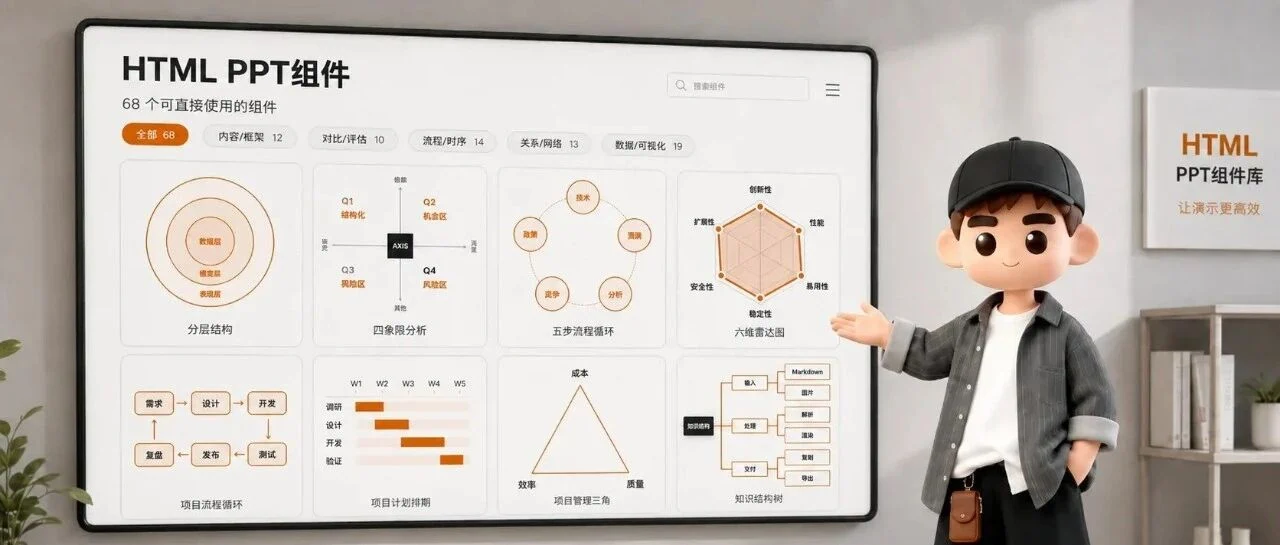
围绕 AI 生成 PPT 容易陷入网格化、模板化的问题,整理 61 个可复用 HTML PPT 组件,把封面、章节页、数据大字报、图片网格等表达模块沉淀成组件库,让 AI 输出从一次性页面走向可持续复用。

围绕 Codex Pro 深度使用经验,提炼启动设定、上下文压缩、成本控制、自检、清理和交付等 15 个实践技巧,让 Codex 少浪费、多交付、更稳定地工作。
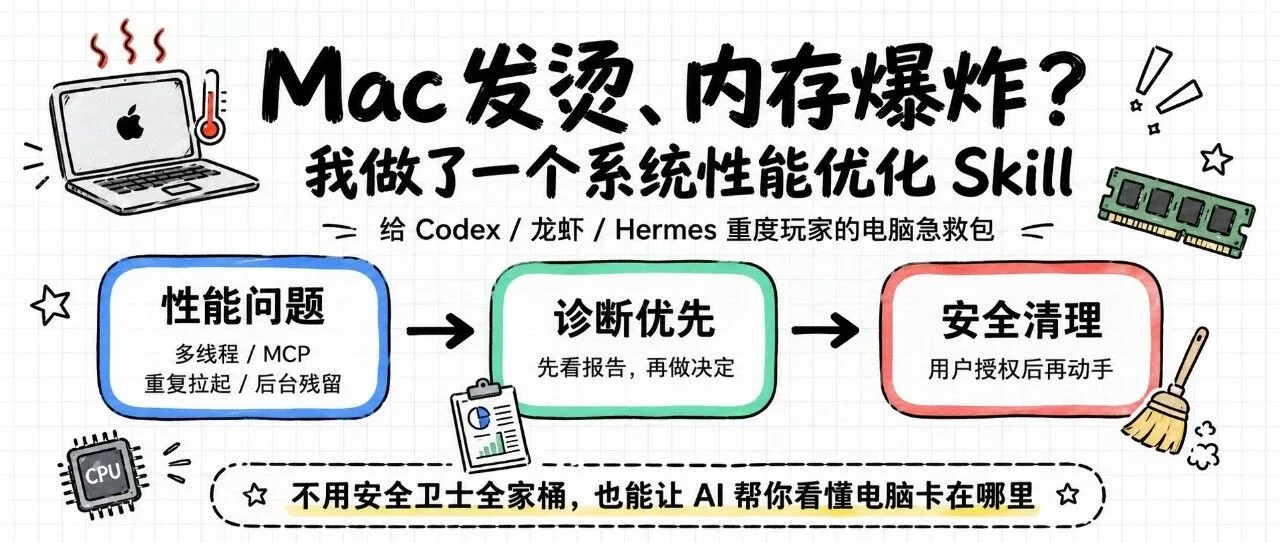
最近重度使用 Codex 多线程跑任务时,MacBook 因 MCP 常驻、残留进程和并行任务变得发烫耗能。本文把 CPU、内存、能耗、磁盘、网络诊断,以及需要授权后执行的低风险清理,封装成开源 optimize-system-performance skill,让本地 AI 能先解释问题、再给方案、最后安全清理。
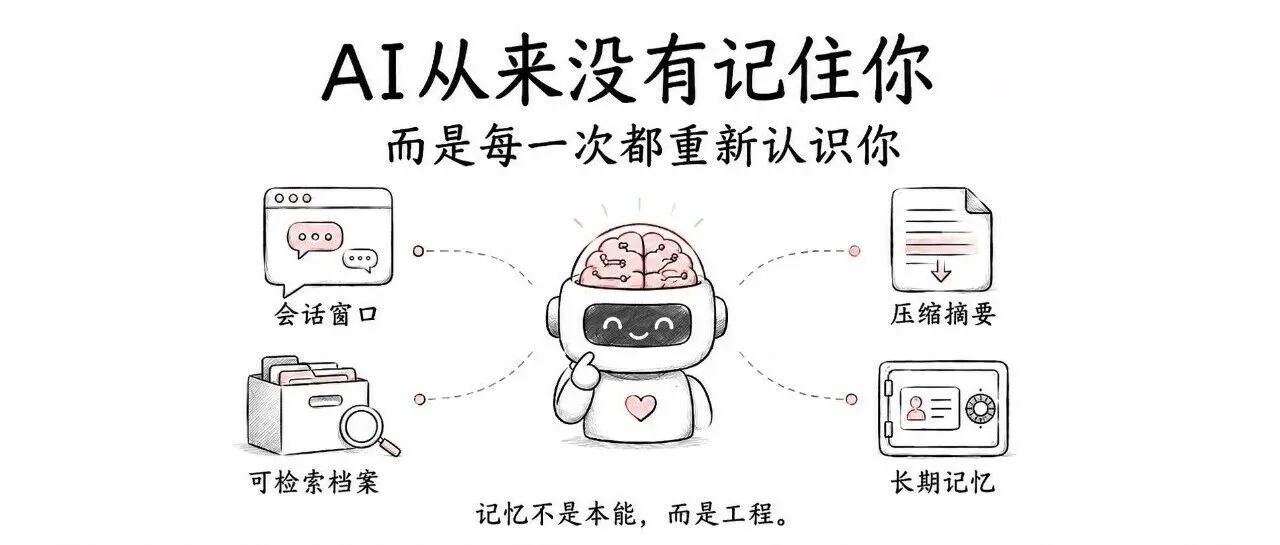
AI有记忆,但不是我们人类的模式。它不是在像人一样记住你,它是在每次对话里重新认识。本文从工程角度拆解AI记忆的四层模型:L1会话窗口、L2压缩摘要、L3可检索档案、L4长期记忆,并解析Hermes自我进化机制与Skill作为记忆延伸的本质。

2026年4月24日,DeepSeek V4 发布了。 它在高难数学、编程竞赛以及编程真实问题验证集中超出了gpt 5.4 xHigh、Claude Opus-4.6Max ,但在专家级知识和推理、终端任务、工具使用能力中落后。

对Manus创始人肖弘的3小时访谈:世界不是线性外推,做博弈中的重要变量,去除部分口语化的语言后进行排序、分类、提炼。 小宇宙:张小珺·商业访谈录 之前的产品做的功能足够用户使用了,大家用的也挺爽的。竞争对手也不卷,还活着的其他的竞争对手也各自安好。
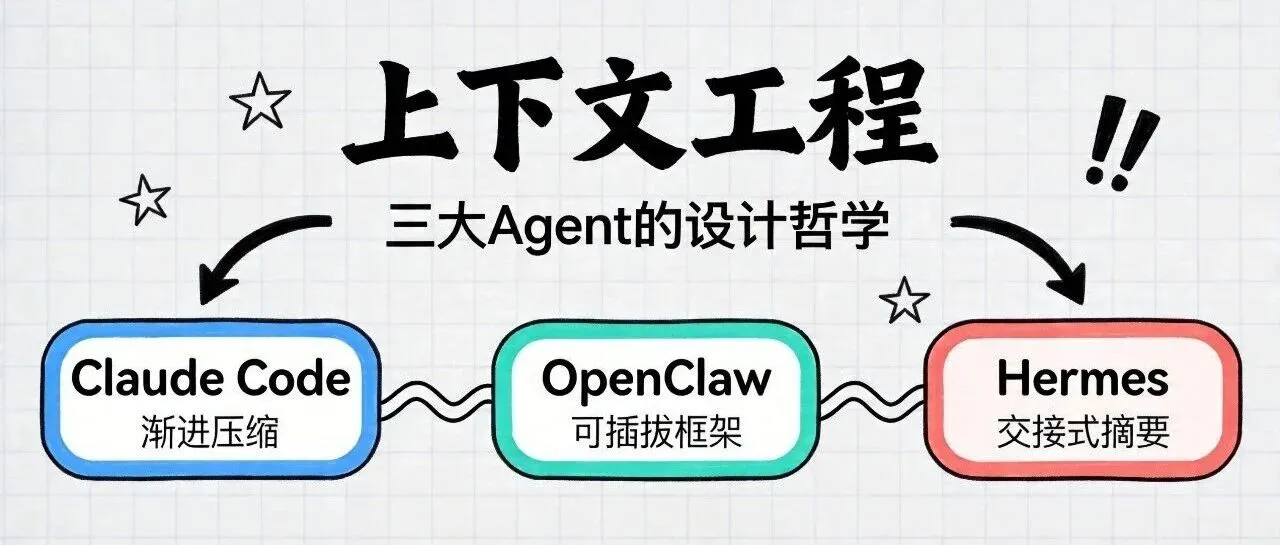
Hermes最近成为了新的热点,除了自我进化机制, 更值得注意的是它在上下文管理上做了不少激进设计,比如更早触发压缩、把摘要做成交接文档。 阐述了Claude Code和Openclaw的Harness机制,能够让AI运行得更加稳定、完善。 在Harness之前,更底层的则是上下文工程,很多时候,模型的幻觉、失忆是因为上下文窗口乱了,

前阵子龙虾大热,但很多朋友都不太能用得很顺畅。 它总会有莫名其妙的中断,接收到了指令没有执行完成,遇到的错误莫名其妙就停下来了,也没有任何反馈。有的时候昨天能正常看的邮箱,总结的邮件,但今天就失败了,就算有skill也不稳定。 原因可能是模型限流了,模型思考死循环了,又或者忘记自己在做什么事情了。
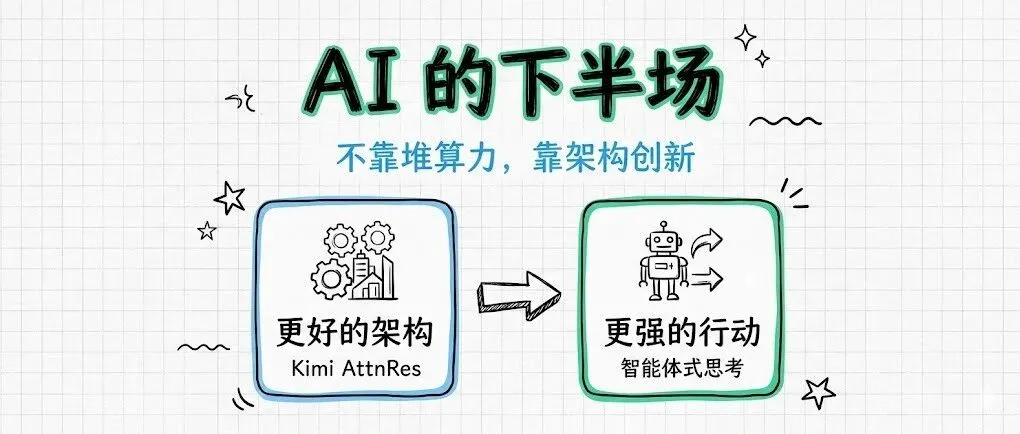
最近特别的忙碌,直到这个周末才有时间阅读 Kimi 的新论文《注意力残差 Attention Residuals》还有林俊旸老师的《从推理式思考转向智能体式思考 From "Reasoning" Thinking to "Agentic" Thinking》。 前者在调整了模型的信息传递机制,让同样的算力训练出更好的效果;后者讨论的是训练目标:让 AI 不仅仅是停留在思考、跑分这些闭卷考试里...

最近又开始折腾提示词了。 复杂的逻辑依靠AI来判别, 如果不开深度思考,那就太慢了,用户等十几秒才能看到结果。

基于上周两场 Openclaw 的培训分享输出本期内容,核心是场景,最简单的生图也尽可能代入业务视角。希望能帮助你了解龙虾是什么,又能做些什么,以及相对友好的安装方式,也有好用、有用的平民Skills推荐,在线版和PDF在文末。 Knowledge Planet 信息爆炸的高效解法,不烧钱了解实用工具。

不知道你会不会和我一样,习惯在一个大屏幕下分屏,左边是终端窗口,右边是浏览器或者聊天窗口。 在等待 AI 实习生帮我们打工的时候,会去处理其他的事情,处理完毕后再会去看终端里 AI 给我们输出的内容,去做规划、做决策。 这样在处理别的事情时,也能够及时看到AI的打工进度,避免耽误AI的时间🐶 但在同时指挥多个AI,或者开启多个任务的时候,电脑桌面会变得特别乱。 查了一圈市场上的产品,都不符合...

网传 DeepSeek V4 最快本周发布。 就在所有人盯着 V4 的参数、能力、benchmark 时,DeepSeek 却悄悄和北大在 ArXiv 上发了一篇论文: 这是一个新的推理框架。它解决了一个更根本的问题: 显卡明明够快,为什么 AI 还是会卡? 这其实是推理系统的KV-Cache读取瓶颈,论文表示 不是算得慢,而是搬得慢,性能被KV-Cache Storage I/O主导。 当...
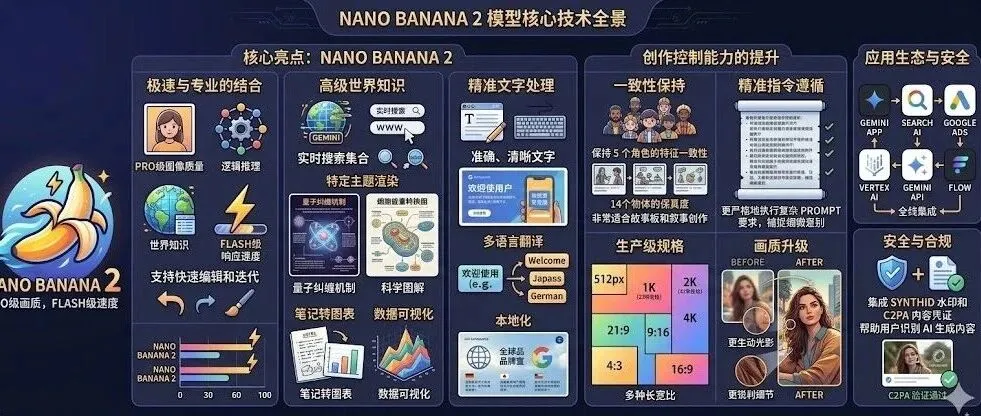
Nano Banana 2,在昨天晚上终于终于终于来了。 熬夜测试了13种有趣的玩法,现在分享给大家。 话不多说,我们,开始。 INFOGRAPHIC 生成百科全书式垂直长图,讲解nanobanana2对比nanobana、对比nanobanana pro的进化 首先我先问了Gemini 这代的Nanobanana有什么进化,几个版本有什么区别,它告诉我们核心是Pro的质量,Flash的速度...
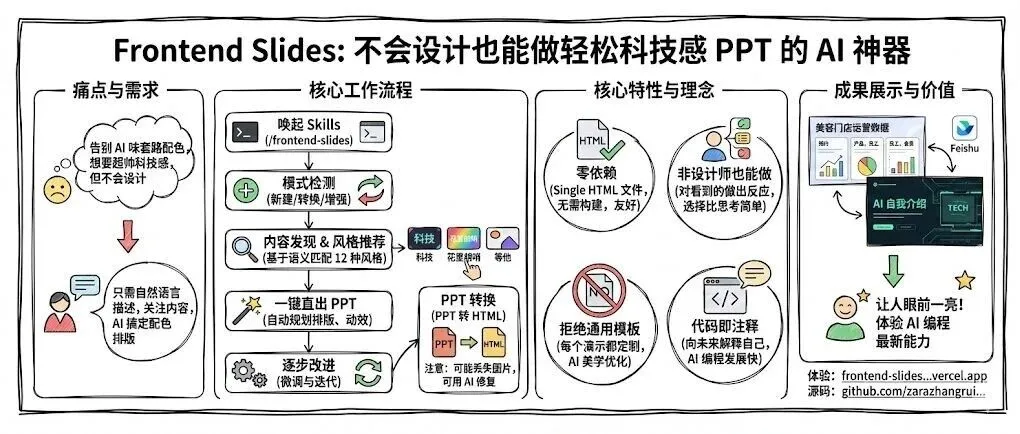
Hi,朋友们,新年快乐。 开年要写年度规划了吗~ 昨天刷Twitter的时候发现了一个宝藏的PPT Skills,可以让大家 告别AI味的套路PPT配色,但是又有超帅的科技感。 以下分别是我用Kimi Code和Claude Code + GLM 5.0用这个Skills输出的效果,左边是Kimi右边是GLM。 用自然语言描述你想要什么,AI就能够帮你把PPT做出来。 你只用关心更重要的每一...

GLM 5.0上线了!!同步上线的还有Zcode。 用户只需把需求说清楚,模型会自动拆解任务, 完成代码、跑命令、调试、预览和提交等开发全流程。 在 Z Code 上,用户甚至可以 用手机远程指挥桌面端 Agent ,解决以往需要很久的工程任务。 GLM-5开源:从代码到工程,Agentic Engineering时代最好的开源模型 这段话看得我特别高兴,赶紧就去测试了Z Code,用手机指...
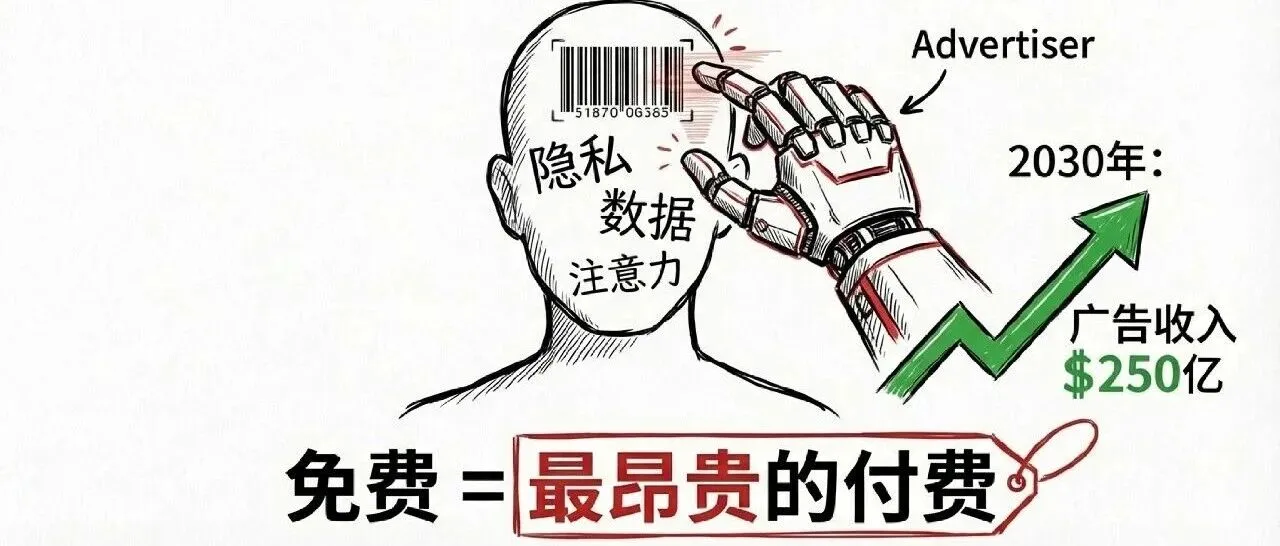
点击星标,及时收看更多AI实战 你和AI说的每一句话,值多少钱? 2026年2月9日,OpenAI 给了这个问题一个答案:20万美元。

这是GPT-5.1 (High)在CL-bench基准测试中的得分。 但这个低分,却是GPT、Claude、Gemini、Kimi、Qwen这些前沿模型中的最好成绩,这些模型平均分仅为17.2%。 CL-bench是腾讯混元团队与复旦联合团队最新发布的基准测试,专门评测语言的上下文学习能力。 它的目的验证模型在真实世界工作的能力。 不要去卷什么乱七八糟的参数,来试试当个生活做题家。 毕竟只有...
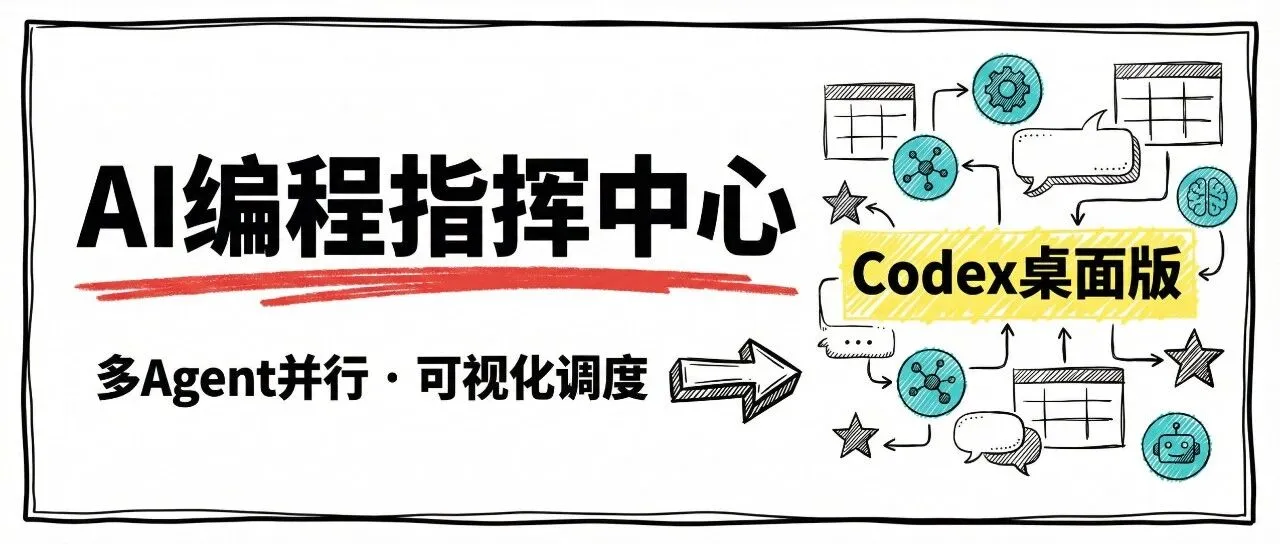
01 AI编程的挑战变了 he core challenge has shifted from what agents can do to how people can direct, supervise, and collaborate with them at scale. 前天晚上,Open AI 发布了Codex macOS应用,它说AI编程的核心挑战已经转移了, 它从AI能做什么变...
最近有很多朋友问我,为什么我的Token消耗量那么大,其实答案只有一个,我把编程CLI代替了所有的事。 无论是调研、规划、编程、数据分析、生图或者创作,它不是我们想象中的只是一个编程工具。

DeepSeek-OCR2 视觉文档理解的革命性突破 📅 2025年1月发布 当传统OCR还在按"左上到右下"的机械顺序扫描文档时,DeepSeek-OCR2已经学会了像人类一样"阅读"。这款仅3B参数的开源模型,以 的准确率登顶OmniDocBench,用 1/7的token消耗 实现了超越Gemini的性能。更重要的是,它将企业级文档理解的成本降低了 💡 核心洞察:DeepSeek-OC...

在前天Kimi K2.5发布了,这次Kimi K2.5对标的是国外顶级的模型,包括GPT 5.2(xhigh)、Claude Opus 4.5以及Gemini 3 Pro。 跨学科的硬核推理、实用的网页浏览、交互和调研Agent拿到了第一 代码、图像和视频能力上逼近第一梯队 ,其中部分测试中超越了国外的顶尖大模型,例如例如长视频场景。 这次Kimi K2.5最强大的变化是 将视觉理解和推理融...

1月27日,DeepSeek在自己官方的Github仓库开源了Deepseek OCR 2 https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf https://github.com/deepseek-ai/DeepSeek-OCR-2 Deepseek OCR 2的核心突破 Deeps...

GLM 5.0上线了!! 学界与业界正逐渐形成一种共识,大模型从写代码、写前端,进化到写工程、完成大任务,即从“Vibe Coding”变革为“Agentic Engineering”。 GLM-5 正是这一变革的产物:在 Coding 与 Agent 能力上,取得开源 SOTA 表现,在真实编程场景的使用体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务。 ...

昨天晚上,阿里悄然发布了一款新模型,Qwen3-Max-Thinking。这个模型的参数规模超过了1万亿,预训练数据达到36T tokens。 在19项权威基准测试中,其性能可 媲美GPT-5.2-Thinking、Claude-Opus-4.5 和Gemini 3 Pro等顶尖模型。 上图是我重制后的表格,我们可以看到在4项基准测试中,千问的表现超过了GPT-5.2、Claude Opus...

最近我发现我陷入了奇怪了循环,在AI时代本来应该让工作变得更高效,但同样流程格式的数据分析,用研报告,每次都要从头开始。 我还是要每次告诉它,这里的数据要用饼图,那个报告的内容要去做真实性验证。 一来一回5分钟过去了。 我在用最先进的人工智能,却做着最原始的重复劳动。 这样的重复,100次也不会让你的成长会变多一点。 直到我发现了Skills。 其实,AI最大的问题不是它不够聪明,而是它记不...

一些吃饭时候的AI乱翻书 来自Tim的提问,Wise的回答
担任 AI 产品经理以后,我最大的痛苦,不是把东西做出来,而是把它做好。 现在做一个60分的Agent真的越来越容易了,扣子、Dify的可视化编排,或者更轻量的知识库产品,把文件丢进去,最简单的Agent就做出来了。

最近一个多月,我一直在用 GPT-5.2 帮我写代码。 不得不说,它的代码质量是真的高,逻辑清晰,边界情况考虑周到。 GPT-5.2 的速度实在是太慢了。 在Extra-High或者High的模式下,我2天就把这周的额度烧完了。 好吧,没办法去开了火山的Coding套餐。 但1月10号买的,1月15号,又烧了一半的Token。 烧的这么快我觉得大概率是我用的比较菜,非编程出身和模型沟通更多的...

实在是被逼的没路走了。 作为一个重度 AI使用者和AI产品经理,我大概每周要修改几十上百次提示词。 以前我以为提示词最大的难点是写出来,需要思考提示词要具备什么能力,要用什么框架,要赋予AI什么技巧。 改提示词比写要痛苦10倍。 每次在GPT和Gemini的对话框里改提示词,感觉和赌博没区别。不知不觉提示词就被改得面目全非。 最可怕的不是改得不够好,而是改得看起来没啥问题。 我说:“把第三段...

唐杰、杨植麟、姚顺雨、林俊旸罕见同台分享,这3个小时的信息密度实在太高了。 同样是大模型,有的人觉得今年和去年差不多,有的人却已经用它把工作方式翻了个面。差别不只在模型本身,更在你站在哪个场景里。 看完分享,最强烈的反差感来自顺雨老师的一句话:
在没有下场做AI产品之前,我很天真的以为写好Prompt就能够做出一个好的AI。但当落地时才发现: 会用AI和做AI产品之间,有一堵厚厚的墙。

疯狂调试N个版本,终于魔改成功了我的ChatGPT年度总结。 我把2025年和GPT对话的数据都给了Gemini,原来我有过1730次发问,经历了3500条信息,输入了240万字。 在11月份时我处在职业的分岔路,和它对话了很久,它说的真好: 十一月的风最大,因为你想去的地方最远。 凌晨5点15分,是我和GPT最晚的对话记录,大概率是失眠了,然后在调提示词。 希望调试的真的是未来,也真的 在...

最近刚写完年终复盘,但到了分享的时候我觉得文字还是太多了,读起来特别累。 在@AI启蒙小伙伴 老师提示词的基础上,疯狂调试了4天,我终于解决了这个大麻烦。 如果你需要做年终复盘、读书笔记、播客摘录或者长文总结,但又不想花时间做排版,这套一键生成高级感PPT的提示词非常适合你。 除了复盘,还有卡片模式,这个提示词也能够很好的帮助朋友们快速阅读。 这是我用十字路口的播客逐字稿生成的卡片,除了克莱...

2025年末,我离开了创业两年半的公司,准备从零到一做一名AI产品经理。 我之前一直相信着:“走过的路,每一步都算数。”但看着这5年的经历:没有代表作、没有垂直的积累,走的每一步都是弯路。

圣诞节快到了,老婆前几天随口说了句今天不知道还要不要买圣诞树,感觉买来买去都差不多,都快审美疲劳了。 @黑波 和 @鱼鱼Cream 老师的3D粒子圣诞树教程,想着自己也用提示词来手搓一个。 一开始不信邪,想着不用Gemini应该也可以。但 GLM改了N轮才改出了这个效果,QwenCode索性是白屏。 GPT在Cursor的表现比在终端要好一些,但还是要反复调整也不太可用。 最后还是认输,用G...

月入5k?AI壁纸可能是最懒的副业。 没花一分钱,没有复杂的提示词,也不用懂摄影和PS,从想法到成图,每次只要1分钟。 前几天想换壁纸,但苹果电脑的壁纸生态非常的弱,没办法直接在steam买壁纸应用,Appstore的壁纸应用也很少。 要么花很长时间大海捞针,要么就去小红书上花钱买,一套6到10块。。 但我换壁纸的频率太高了,长期付费也不现实。 而无论是应用还是小红书,付费买的壁纸AI痕迹很...

前几天参考 @摸鱼的小李 老师的PPT提示词,迭代了 一次性生成、PDF下载以及图形绘制能 试图用这个提示词解决我的PPT噩梦,但输出还不是特别稳定。 又再花了3天调整提示词结构,增加了分类型规划内容的能力,好消息是这样的输出终于比较稳定了,元宝的R1也能跑出来 坏消息是,最后的5分钟研究了一个新玩法,……&*¥#^, 一句话还真的能做PPT啊。 你是一名专业的PPT设计师,请基于文...

作为打工人,PPT是一直逃不脱的噩梦,而更可怕的噩梦是又快又好看,但再厌恶paperwork,为了生存也得上。 传统方法耗时耗力,本来以为AI是个救星,但测试了几款发现大多都是一波流,要自己改或者有限度的改,文字的堆砌感也非常重,要变好就要我加钱了🐶。 于是,我决定,自己折腾!以下是肝了3天的成效(优雅。 我把段永平的50条语录发给了AI,让它们帮我做PPT Kimi做的,坦白说视觉表现上,...

在AI自媒体上迈出了小小的一步,WayToAGI和飞行社都收录啦~值得开心,也分享一下整合的全文。 提示词做卡片已经不新鲜了,然后最近思考了下能不能在提示词的基础上往前走一步,于是用飞书多维表格制作了一个AI文章阅读系统。 提示词参考了云舒老师的思路,进行了简化,优化一下性能,并且用于适配飞书场景。 最核心的问题其实就是,文章收藏了懒得看。 1、输入链接,输出卡片 省去了复制内容给AI的环节...

上一篇文章分享的阅读管理系统,有很多朋友去使用了。 但很快有朋友反馈,手动复制内容还是很麻烦,尤其在手机上。其次卡片的信息还是比较少,看完害得纠结值不值得读。 输入链接直出张高质量的速读卡片。 2.0版本解放双手,卡片知识密度翻倍,阅读焦虑瞬间清零。 用同一篇文章来对比一下差异。 简单文字拼接,就像速览笔记。 2)横版:信息密度提升,重点一目了然 3)竖版:彻底解决速读问题 竖版手机友好,而...

看到一篇好的文章,下意识点个收藏想着晚点再看,然后它就和上千个链接一起,被埋进名为“收藏”的坟墓里。 那种“假装学习”的满足感,转眼就变成了无尽的阅读焦虑。 每次打开几百篇的收藏夹,总是一脸茫然:当时为啥要收藏,讲的是什么,信息会不会过期了。 直到最近用Deepseek、Kimi,还有飞书多维表格,给自己搭建了一套阅读管理系统。 1)1分钟生成速读卡片 把内容和链接丢进去,Kimi会立刻提炼...

花了 1小时,复刻出了巨头强化版的“自己”。 他不仅能够回答问题,还继承了600+份马斯克、乔布斯、王兴等巨头的演讲、访谈的理念,融合了我自己知识积累,让我站在巨人的肩膀上思考。 现在我们想问一个问题,第一反应是问AI。 但AI的回答容易泛泛而谈,打开联网搜索, 数据源存在大量噪声,重复、二次加工、低质量的知识远多于高质量的知识,而如果不打开联网搜索,知识可能滞后。 更关键的是它不知道我读过...

花了5分钟,我用GPT+NANO BANANA给自己的小猫做了几个手办,效果真的非常惊喜。 手绘、表情包、高糊的照片,都能够立体化还原成小模型。 它能够自动补全缺失的肢体细节,还恰好的猜中了我家小猫是小胖子。 清晰度部分提升明显,体态也会做优化微调,这里我最满意是我小猫鼻子的痣也能够被很好的还原,目前大部分的AI生图都很难找到这个细节。 而表情包,也能够很轻松的变成立体的画面,调整姿态。但如...

在去年7月的时候,我就在思考一个问题,怎么样补充企业的销售能力。 它的工序要足够简单,不然我做不出来。它也不能太简单,不然我抢不过别人。 它的盈利模式要足够直接,不能赔本赚吆喝。 它未来要能够标准化,不然我开不了连锁店。它还要有延展性,具备可持续的发展空间。 这个方向,在一开始就被我否定了, 周期长,就无法敏捷试错。成本高,失败的代价就越沉重。但最大的理由是:千行百业,我不知道要选哪个方向,...

前阵子有朋友留言问是否能用Cursor开发一个小程序呢,答案当然是可以的。 小程序比较友好的地方是云开发衔接的比较好,我们不用去理解太多域名、SSL证书、服务器的逻辑。 而个人的小程序除了不能开通支付以外其他还相对友好,今天会分享怎样用Cursor+小程序云开发一个简单的小程序。 先放一个自己做的练手的小程序,以防口嗨。 https://mp.weixin.qq.com/ 这个页面选择小程序注册。

前两篇文章分享了先开发原型再优化设计的Cursor+MCP的使用方法,但这种方法比较适用于没有产品背景的同学,但由于21magic和Cursor还是存在一些兼容问题,会比较费时和费request。 《Figma无痛画原型,一键直出设计稿和代码》 分享了通过AI直接提供设计稿的方式,当有了设计稿下一个环节就是开发。 在编码的环节,建议是先开发界面,再开发逻辑。 先看看实现效果,可以注意到顶部的...

前几天实验了Cursor怎么和MCP联动设计高保真的原型图,这两天发现我忘记了一件事: 其实Figma其实已经可以设计出UI了。 而Figma是一个很好的原型工具,能够自定义对UI进行微调,先做设计再开发,比起先开发再优化设计要高效的多。 Figma无痛绘制设计图 1、访问Figma并注册登录 https://www.figma.com/ 2、点击右上角创建一个文件 3、点击底部操作栏,唤起...

相信大家已经看到了非常多Cursor生成原型的实战教程,今天会在这个的基础上,补充Cursorrules和MCP的应用,帮助大家提升效率和质量。 怎么样让cursor给你做一套高保真原型 先上提示词,提示词最早我个人应该是从花生老师那里看到,然后从阿紫老师那里看到了进一步的优化版,优化点主要在于真实感增强部分。 现在需要输出高保真的原型图,主要功能包括 请通过以下方式帮我完成所有界面的原型设...

在去年7月份我才开始正儿八经拥抱AI,大概也算赶上了AI的晚班车,最早开始玩的是文本生成,然后是图片、视频、编程。 我尝试过用AI来画儿童绘本,但生成的效果总是差强人意,对中文的适配也不友好,而liblib又过于复杂,所以搁置了。 前几天OpenAI上线的GPT-4o生图功能,今天充了个钱实测了一下,充钱果然能变强。这一切都不一样了, 我不再需要翻译、垫图也不再需要复杂的工作流,它也不再那么...

3招学会自我介绍,打败99%的面试者 最近在招聘B端产品,面试了百来个人,大部分人在说完自我介绍就接近被淘汰了 他们到底犯了什么错呢? 美国心理学家提出了一个概念叫“首因效应”,即“先入为主”会影响人们对他以后一系列行为和表现的解释。 如果一开始我就觉得无聊,后面他说的什么我都会往无聊联想 面试官的精力、时间都有限,要看很多的简历,面试很多的人。 想要更高概率通过面试需要帮面试官...

最近看了篇文章说现在很多小红书的达人其实是AI画出来的,然后批量做矩阵。其次很多人也在用AI绘画做简单的头像、壁纸售卖。 虽然还没有想好要做什么赛道,但也许播下足够多的种子就能够开花。 作为一直画画很差劲的同学,也想着能够比较熟练的掌握这门技巧,于是开始实操研究AI到底能够帮我画什么。 测试的5-6个工具里面,比较好用的还是MJ、Liblib。MJ的操作更加简单,Liblib则更加专业,但目...

最近忽然间被自然流眷顾了,感到非常开心。9月底分享的 《产品架构图怎么画?附14个高质量架构图》 拥有了接近3000次的分享,真的非常感谢每一位读者。 对架构图模版的需求,让我忽然发现做PPT真的是职场人的痛点。 在大厂磨炼过也算是练出来了,在职场里落地只是本分,我们不仅要学会想故事,但最重要的还是学会讲故事, 在我看来做PPT只有3招: 梳理逻辑、寻找模型、视觉优化。 第一点是最重要的一点...

很多朋友问我到底要怎么快速成长为优秀职场人,其实学习能力不是天生的,是培养出来的。 在我看来核心分为3点: 1)掌握优秀的思维模型,拥有正确的思考方法 2)熟悉各大分析框架,全面且符合逻辑的分析问题 3)结合实际分析问题,掌握分析问题的步骤 思考得不够严谨,拥有框架也没有用,更别说分析实际的业务问题。职场竞争力的核心是:方法论+业务知识。 拥有充足的方法论能解决不同的问题,掌握丰...

今天分享的是腾讯产品能力模型:竞品分析。它隶属于能力模型的第一项:市场分析。 市场分析更偏宏观,主要在回答 ,如果都是肯定的,那么竞品分析会更聚焦一些。要回答的是要 怎么做以及怎么做得更好 P7及以下,需要明晰的宏观的环境、动态,要求 P8-P9,细化到定位、趋势,产品侧细化到模块级别。并且要求具备 分析能力、处理能力,发现机会,能落地为短期规划。 P10及以上,需要独立负责完整的市场分析,...

由产品抽象而成的模块化、层次化的架构,体现不同层级内外的交互关系,包含功能模块的组合、数据和信息的流转。 用于传递产品的业务流程、发展方向以及产品的设计思路。 俗话说:不会做饭的产品不是好的建筑工。 假如把房子比作产品,居住者是我们的用户,产品架构描述的是房子的构成,产品是房间,功能是房间里的家具,中台服务是某类供应商例如家电、床品,而底层能力是最原始的石头、木头。 围绕产品目标及商业模式,...

上次分享的短视频是用claude生成了代码,但在编程的过程其实应该更加沉浸。 我在学swiftUI的时候也会很想Xcode能不能告诉我原因是什么?然后直接帮我直接改BUG,甚至更懒一点能不能基于我的想法直接生成一个能部署成App的代码。 《中秋3天,足够你用AI编程,做个赚钱小产品》 ,作者Time教朋友们怎么用 Claude+Cursor 生成游戏、爬虫的教程。 教程基本算是测试成功了,这...

来到传统私企后,发现很多人还停留在明细数据的阶段。相对好一些的,却是被毒害的青年,开局RFM、帕累托,然后解密宇宙。 提起数据分析,很多人容易陷入过于复杂的模型和工具中, 为了“打破迷信”也为了有一份相对能看的数据 ,决定写一篇易于理解的保姆级实践指南。 数据科学,不是量子力学 无论多么高大上的语言或工具,数据分析绕不过这3点 获取数据、清洗数据、理解数据。 它的难,难在热搜里充斥着不实用和...

-- NO.30 -- 这是Wise的第30篇文章 全文约3439字,建议先收藏看看 好久不见,上一次更新还是在上一次,发长文大概是2年前。总算在一个相对稳定的环境、情绪里写些东西,没意外的话,应该会恢复更新。那就接着上一次,写写22年发生的事情,就当炒个冷饭。 21年下半年结束匆匆半年的游戏直播,开始了一年半的元宇宙,也没想过一直都在做中后台的我会走上这条路。这里已经是说得出口的...

AI编程是很好的实现个人想法的工具,但在落地的时候我们应该评估其实现方案。如果你的流程并不复杂,也没有什么算法流程对接复杂API的时候,个人建议还是使用Coze。 扣子是字节的无代码应用开发平台,在工作流场景核心提供2大能力: 如果你不需要界面,也不需要变成一个AI会话应用,那其实只要建立工作流就可以使用了。 今天要给大家分享的是怎么样 使用扣子打造社群日报的工具 ,学习了基础的用法,我们也...

-- NO.28 -- 这是Becomewiser的第28篇文章 很多朋友问我之前在做些什么。说得比较多,也说得比较散。先说一下半年前只做了半年的事吧,做个记录。 如有雷同,那就是我编的。 在社交平台做游戏直播,乍一听确实是一件较难理解的事,但如果尝试从社交解题则会容易的多。 社交关系,可以粗略划分为:陌生人、半熟人、熟人。 一般的社交平台会选择一种关系作为核心,当发展到了一定的阶...

-- NO.27 -- 这是Becomewiser的第27篇文章 返乡过年,迎接大年初一的不再是城市里的难忘今宵,而是农村里的烟花、鞭炮和约定俗成的断网。 伴着阴雨,这一刻也算是辞了旧也迎了新,一切又重新开始。我总觉得时光匆匆,但却只是给自己拧了太多圈的发条。 超负荷地运转了太久,崩溃的时候计划就再也没办法应对变化。 在新年的所思所愿是慢下来。去感受变化,探寻未知和陌生,能够恰逢其...

-- NO.26 -- 这是Becomewiser的第26篇文章 全文约3597字,建议先收藏看看 这个话题的缘自于微信视频号开放了移动端游戏直播,一开始还奇怪为什么只开放了几款游戏,尝试开播后才发现它和传统的录屏直播能力大不相同。 将玩家在游戏操作数据,经由云端将数据还原成直播画面 。目前只有对局画面是1:1还原,而其他的画面都是模拟生成。 对比传统方式,其不占用手机性能和流量,...

-- NO.25 -- 这是Becomewiser的第25篇文章 全文约3324字,建议先收藏看看 Hi,断更数月,好久不见。 这段时间,我的工作、生活节奏发生了很大的变化,直到这两周才调整回来。痛苦又艰难,好在也想明白了一些事。 所以也想和朋友们聊聊怎么样去适应一个新团队,近期所得可以分为三个部分: 个人诉求、职能、模块化执行 第一个部分是为了心安,后面两个则是为了做事。 01&...

-- NO.24 -- 这是Becomewiser的第24篇文章 全文约8851字,建议先收藏看看 “用户画像”、“用户标签”、“大数据”这些名词是我们近些年来常听的词,可是这些词却很难直接的产生价值,我们都知道大数据有用,画像也有用,但到底怎么用?又怎样具象成一个产品却很少人能够说清楚。 如何采集数据,形成服务再到供给运营,这也是这篇文章想分享的核心。 在市场上神策、易观数科会将...

-- NO.22 -- 这是Becomewiser的第22篇文章 全文约2801字,建议先收藏再看 这篇文章的主题其实转换了很多次,可能在正式离职的前夕,才知道自己想表达些什么。 关于选择,这次核心想谈的是:去或留、小厂或大厂、专业性或全面性。 去或留,想描述的是是否要离职。 这个问题之前会有一个更前侧问题 个人的观点是,面试是有必要的,只是需要选择较为恰当的时机。 个人在社会、企...

-- NO.23 -- 这是Becomewiser的第23篇文章 全文约3770字,建议先收藏看看 截至2020年12月我国网民规模为9.89亿,网络普及率约70.4%,根据《第7次人口普查公报》人口预估,2021年网民规模约为9.92亿, 移动社交及游戏增速放缓的前提下,尝试探索移动社交及游戏的增长的方向 本文选取产品样本为 QQ 及 王者荣耀 。 01 市场规模 1...

-- NO.16 -- 这是Becomewiser的第16篇文章 全文约2609字,建议先收藏再看 体系,是一定范围内同类的事物按照秩序联系组合而成的整体。 用户运营体系,则是用户需求与企业需求的结合,是面向双方的解决方案。 规划用户运营的体系,其目的为厘清业务运作模式及提前做好能力储备,便于后续进行产品规划。 近期在思考体系规划时,也尝试着归纳 符合逻辑且较为通用的方式。 本文将...

-- NO.15 -- 这是Becomewiser的第15篇文章 全文约2718字,建议先收藏再看 在电影《教父》中,有一句台词:“在一秒钟内看到本质的人和花半辈子也看不清一件事本质的人,自然是不一样的命运。” 为什么你只能看见的是豹子身上的花斑?为什么看到本质的人和他人的命运会不同呢?这是因为他人的知识水平比你更加全面,更加深刻。 选择面更广,每多掌握一门知识,就多一种未来。 其...

-- NO.14 -- 这是Becomewiser的第14篇文章 全文约2756字,建议先收藏再看 1 为什么要做A/B实验? A/B实验,是一种验证假设的方法,其核心方法及原理分别是 在实际实验时会从总体抽取部分个体组成样本单位,并从个体实验结果推断总体结果。 ,能通过对比发现因果性,并根据实验结果量化正向和负向的影响程度。 当实现了某个新的特性,我们无法准确预估上线...

-- NO.13 -- 这是Becomewiser的第13篇文章 全文约2502字,建议先收藏再看 LTV和DAU是运营中常常接触到的词,这2者的计算 高频的发生在“缺乏数据”的时候,产品上线前要预估其ROI及回报周期,决定是否立项。上线后又需要根据LTV及DAU,不断调整运营策略。 在缺乏数据的时,决策总让人头疼。本文将介绍在缺乏数据时LTV及DAU的预估方法,也会详细的介绍公式...

-- NO.11 -- 这是Becomewiser的第11篇文章 全文约7373字,建议先收藏再看 数据分析的下限,取决于逻辑归纳。与其说 提高分析质量,不如说提升逻辑归纳能力。 逻辑归纳,需要拥有良好的逻辑思维,并结合领域知识形成该领域的分析方法。而领域方法,进一步归纳则能够成为通用了方法论。 关于数据分析,本文将从 2个角度进行解读,其中分析方法会介绍数据分析前的准备以及 如何...

谈及用户画像,我想产品和运营的朋友们都不会陌生,用户画像是用户研究的重要输出,它能帮助我们更好的进行业务决策以及产品设计。 用户画像落实到产品设计,本质上是 将数据组合成数据特征,从而形成用户的数据模型 构建用户画像的主流方法有4种: 前两者是基于已有数据的构建方法,其缺陷是无法处理数据缺失或不在规则范围内的用户。 而解决这一类问题,也正是机器学习存在的意义,它让计算机像人一样去学习处理问题...